
Warning: Undefined array key 4 in /home/meigetz/linnameigetz.com/public_html/wp-content/themes/lovecraft-child/functions.php on line 62
Warning: Undefined array key 6 in /home/meigetz/linnameigetz.com/public_html/wp-content/themes/lovecraft-child/functions.php on line 67
Warning: Undefined array key 8 in /home/meigetz/linnameigetz.com/public_html/wp-content/themes/lovecraft-child/functions.php on line 72
Warning: Undefined array key 10 in /home/meigetz/linnameigetz.com/public_html/wp-content/themes/lovecraft-child/functions.php on line 77
こんにちは。めいげつです。
語彙(ボキャブラリー)の増強は、英語学習者にとっての永遠の課題。語彙を増やそうとして、単語帳とにらめっこという方は多いのではないでしょうか。
しかし単語と日本語訳を1つ1つ覚えて行っても退屈だし覚えが悪い……何を隠そう、僕もこのパターンです。
単語を覚えるにはたくさんの例文に触れるのが一番。でも例文なんてそんなにたくさん見つからない……という方。
そんなあなたのために、コーパスというものを紹介しようと思います。
<記事は広告の後にも続きます>
コーパスとは何か?
コーパス(corpus)とは、言語のさまざまなテキストをデータベースに集積した資料をいいます。言語学の研究のために使われることが多い資料です。
新聞や本、文字に起こした会話文など実に様々な種類のテキストが集められていて、ある単語がどんな場面でどう使われるかを具に調べることができます。
コーパスを英語学習に使うメリットとして、コーパスには膨大なデータがあるため、単語のさまざまな状況での使用例を見ることができるということです。
違ったコンテクストで使われている例を見ることができれば、単語がより定着しやすくなりますよね。
ちなみにcorpusという単語はラテン語由来で、複数形はコーポラ(corpora)といいます。
<記事は広告の後にも続きます>
コーパスの一覧
SkELL

おそらくコーパスの中でもかなり使いやすいのがSkELL(Sketch Engine for Language Learning)。
前に紹介した2つのコーパスはどちらかというと言語学を学ぶ人向け。こちらは英語学習者が例文を探すことにフォーカスしたもの。
UIがシンプルで、検索窓に調べたい単語を入力するだけ。そうすれば、その単語が使われている文がずらっと出てきます。例文が欲しい場合はまずはこのコーパスを使うのが良いでしょう。
BYU Corpora
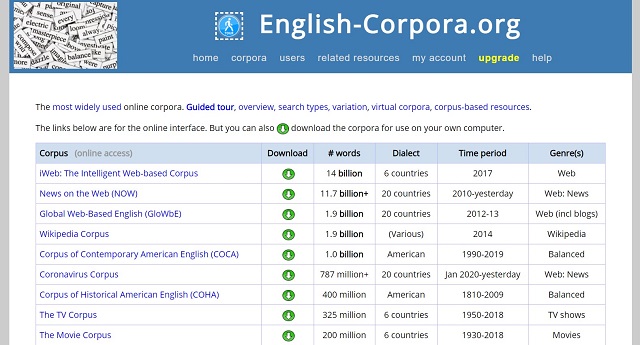
BYU Corporaは、アメリカのブリガム・ヤング大学(Brigham Young University、BYU)が公開している英語のコーパス。言語学界隈ではおそらく超有名なコーパスです。
BYU Corporaは数種類のコーパスを集めで、例えば
- 現代アメリカ英語コーパス(Corpus of Contemporary American English, COCA)……会話、フィクション、大衆雑誌、新聞紙、学術テキスト、テレビや映画の字幕、ブログなどのウェブサイトから蒐集した10億語を超えるコーパス
- The Intelligent Web-based Corpus(iWeb)……ウェブの資料をベースにした140億語からなる膨大なコーパス
- Corpus of Historical American English(COHA)……1810~2000年代の資料を集めたもの
- Corpus of Global Web-Based English(GloWbE)……世界様々な地域から英語の資料を集めた
……といったコーパスが15種類以上あり、目的に合わせて調べ物をすることができます。
アカウント作成は名前とメールアドレス、パスワード、自分のステータス(学部学生か院生か、教授科などから1つ)を選んで登録すると、メールが届きメール上のリンクをクリックすれば本登録されます。
BYU Corporaは無料で使えますが、時たま検索した時に「プレミアムにアップグレードしませんか」というメッセージが出ます(しばらくすると「続ける」というリンクが出現します)。
The Leeds collection of English corpora
The Leeds collection of English corporaは、イギリスのリーズ大学が運営している、インターネットの資料をベースにした英語のコーパス。
British National CorpusやBritish Academic Spoken Englishなどといった複数のコーパスを合わせたもので、単語がどんな文脈で使われるのか、どんな単語が一緒に使われるのか(=コロケーション)を調べることができます。
こちらは無料でアカウント登録なしで使えます。ただ正直UIが洗練されておらず、BYU Corporaに比べて使いにくい感じが否めません。
<記事は広告の後にも続きます>
英語学習でのコーパスの使用法
ここでは、例として先ほど挙げたBYU Corporaの中にある、現代アメリカ英語コーパス(Corpus of Contemporary American English, COCA)の使い方を紹介します。COCAは、5億6000万語の膨大データからなるコーパスです。
コーパスを開きながらお読みください。
単語の使用例を見る方法
COCAにアクセスしたら、調べたい単語を検索窓に入れて「Find matching strings」をクリック。
するとその単語が使われる頻度(=frequency)が表示され、青字になっている単語をクリックすると、その単語が使われている文のリストがずらっと表示されます。
リスト上の文はそれぞれ中途半端に切れていたり文脈が分かり辛かったりしますが、リストの項目をクリックするともうすこし長い文章が表示され文脈が分かりやすくなります。
コロケーションを調べる方法
COCAにアクセスしたら、「List」、「Chart」の右にある「Collocates」をクリック。検索窓が2つある画面が表れます。
上の空欄に調べたいに単語を入力します。たとえばdeepのような単語です。
もしdeepの後ろに来る名詞を知りたい時は、その下にある空欄にNOUNと入力します(ここは後ろにくる単語の品詞を大文字で入力しましょう。形容詞ならADJ、動詞ならVERBという具合です)。
下の検索窓のさらに下にある数字、真ん中の四角の右側にある数字をクリックしてハイライトさせます。この場合は1(=deepの直後に来る1単語だけ表示)がいいでしょう。
この数字の並びですが、これは調べる単語の前or後ろに来る単語の数を表してます。まず数字をクリックすると数字がハイライトされ、ハイライトされた分の数の単語を比べられます。「2」にハイライトすれば2語です。
そうしたら頻度の高い順にbreath、water、breaths、space、voiceと出ました。deepはこういった単語の修飾に使われることが多いのですね。
2つの単語のコロケーションを比べる方法
「Compare」をクリックします。そうしたらWord1とWord2にそれぞれ調べたい単語を1つずつ入力して、3番目の空欄に品詞を入力します(例えば後ろにくる名詞を比べたい場合はNOUN。調べたい単語の品詞ではありません)。
「Collocates」と同様に、直後の単語を比べたい場合は右側の数字をクリックしてハイライトさせます。それで「Compare words」をクリックしましょう。
smallとlittleの後ろにはどんな名詞がくるのか比べたいときは、smallとlittleをそれぞれ空欄に入力して、3番目の空欄には「NOUN」と入れ、数字の並んでいるところでは右側の数字をクリックしてハイライトさせます。それで「Compare words」をクリック。こうすれば意味が似ている2つの形容詞が、どんな名詞を修飾するかを比べられます。


<記事は広告の後にも続きます>
まとめ

いかがでしたでしょうか。以上、コーパスを使って英単語の使用例やコロケーションを調べる方法を紹介しました。
英単語を覚える時、単語帳とひたすらにらめっこするのも良いですが、やはり実際のコンテキストといっしょに覚えるほうが定着しやすいものです。
こういったリソースを活用すれば、様々な文脈で使われている例が見られますので、分からない単語があったら、コーパスに投下してみることをおすすめします。


Header Image by Arulonline on Pixabay
コメントを残す